Содержание
Технологии поискового маркетинга
Разработчики поисковых систем обращают наше внимание на то, что необходимо писать тексты для людей — полезные, интересные, информативные. И это не только слова: алгоритмы Panda и «Баден-Баден» не щадят страницы со слабым контентом и вытесняют их далеко за пределы ТОПа.
Что есть некачественный контент?
На этот вопрос мы постарались найти ответ в анализе последствий введения нового фильтра Яндекса.
Наряду с такими признаками, как
- чрезмерный объем,
- плохая читабельность и
- смещение текста из видимой зоны, о низком качестве контента говорит
- неестественность языковых конструкций.
Именно об этом — качестве изложения — мы поговорим в новой статье и разберемся, при чем тут LSI-фразы и как с ними работать.
Что такое LSI
LSI-копирайтинг (LSI — аббревиатура от latent semantic indexing, что в переводе с английского языка означает «латентное семантическое индексирование») — методика написания и подачи текстового материала, повышающая его релевантность при анализе синонимов, слов, сопутствующих ключевому запросу, а также содержания и смысла текста поисковой системой.
Термин LSI стал звучать в профессиональной лексике оптимизаторов с запуском Google алгоритма Panda («Панда»). Но наиболее пристальное внимание ему стали уделять после прорыва поисковика в области семантического поиска и запуска алгоритма Hummingbird («Колибри»). Поисковая машина начала оценивать релевантность контента не столько на основании вхождения ключевого слова, сколько по степени смыслового соответствия текста исходному запросу. Над реализацией аналогичного подхода сейчас трудится и Яндекс.
Робот не просто цепляется за ключи как якоря, а сканирует и анализирует все содержание (контекст), что делает его оценку близкой к оценке человека.
В связи с этим закономерно появились термины LSI-фразы и LSI-копирайтинг. Они подразумевают расширение основного запроса, а именно: поиск его синонимов и сопутствующих тематических слов (латентных, то есть неочевидных ключей) и написание на их основе качественного материала.
Вместо расчета плотности и тошноты в дело вступает осмысленный подход, в основе которого лежит семантический анализ.
Цель этих действий — дать пользователю наиболее полный ответ на запрос, представить предметный текст в удобочитаемом виде.
Чем отличается LSI-текст от SEO-текста
Рассмотрим на примерах разницу между SEO-текстами и текстами, в которых учитывается LSI. Зададим в Яндексе запрос «купить эллиптический тренажер» и посмотрим на уровень качества контента сайтов с разных позиций.
На рис. 1 — описание раздела каталога интернет-магазина за пределами ТОП50. Мы видим изобилие основного ключа (12 раз в коротком тексте!). Копирайтер в точности подогнал текст под указанные запросы, отведя информативности и удобочитаемости второстепенное значение.


На рис. 2 — текст магазина из ТОП10, претендующий называться естественным и информативным. Единственное замечание касается врезки о сервисных услугах с целью добавить на страницу ряд коммерческих ключей: «доступные цены», «большой выбор», «гарантии», «скидки», «доставка» и т. д. В данном контексте эта информация не несет полезной нагрузки.


Текст из второго примера являет собой не просто набор слов, а смысловую единицу. Если скрыть в нем основной ключевой запрос «купить эллиптический тренажер», смысл не потеряется и из контекста мы поймем, о чем идет речь. Попробуйте сделать то же самое с текстом из первого примера — можно подставить любой другой вид тренажера и ничего не изменится, что говорит о шаблонном формате контента.
Далее рассмотрим, как построить основу (найти ядро запросов) для создания качественного релевантного текста, обогащенного LSI-лексикой.
Как найти слова для LSI-ядра
Начнем с того, что LSI-фразы условно можно разбить на две категории: синонимичные и сопутствующие (связанные тематикой с основным запросом). Первая группа слов позволяет избежать многочисленных повторов ключа, вторая — раскрыть тему текста. Можно предположить, что это будут НЧ-запросы, но это не совсем верно. LSI-фразы связаны по значению с основным запросом, и в их числе могут быть разные по частотности слова и словосочетания.
В нашем примере с эллиптическими тренажерами синонимами основного ключа могут быть:
- эллипс,
- эллипсоид,
- эллипсоидный,
- орбитрек.
Дополняющие тематические слова:
- беговая дорожка,
- степпер,
- кардиотренажер,
- велотренажер,
- лыжи,
- спортивное оборудование,
- домашний,
- профессиональный,
- для пресса,
- для похудения,
- для ходьбы,
- для спины,
- складной,
- магнитный,
- купить тренажер,
- цена,
- магазин и так далее.
Вопрос в том, как собрать это ядро запросов. Рассмотрим несколько бесплатных способов.
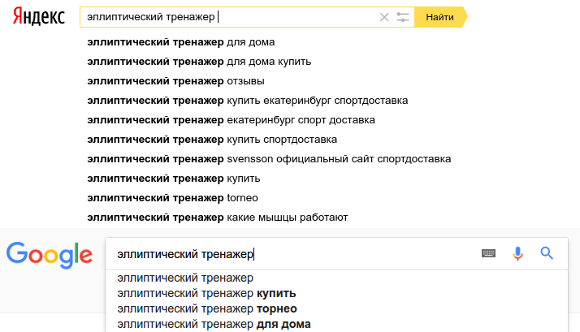
1. Поисковые подсказки
Изучаем актуальный поисковый спрос в рамках искомого запроса. Яндекс выдает десять поисковых подсказок, Google — всего три.

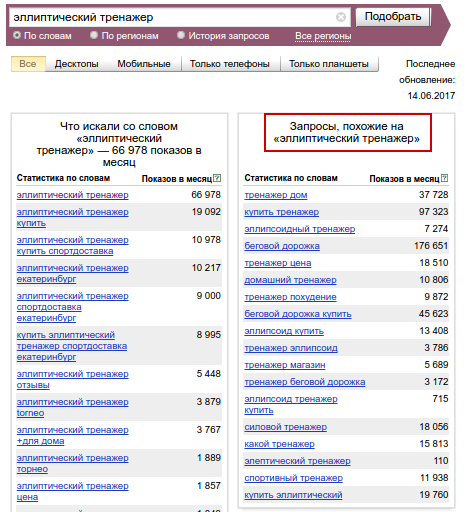
2. «Яндекс.Вордстат»
Находим «Запросы, похожие на …» в правой колонке сервиса «Вордстат» (рис.4).

3. «Вместе с этим ищут»
Смотрим на рекомендации Яндекса и Google, основанные на других интересах людей в рамках искомого запроса. Блок располагается в нижней части страницы с результатами поисковой выдачи (рис. 5).


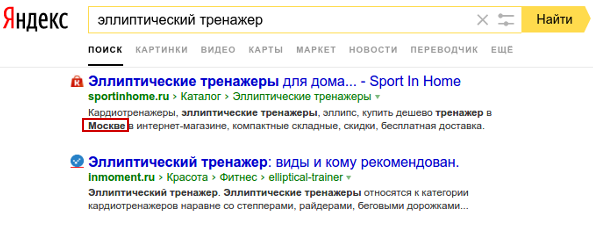
4. Тексты сниппетов в ТОП10
Ранее для поиска дополнительных слов можно было использовать поисковые подсветки Яндекса (выделенные слова в сниппетах наряду с искомым запросом). Однако сейчас в подсветках ничего кроме региона найти не удастся (рис. 6).

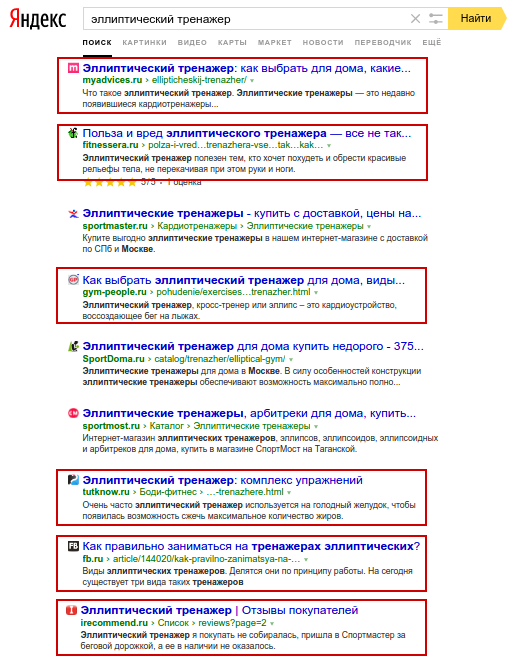
Так как подсветки более не помогают, можно использовать другой вариант работы со сниппетами — просмотреть тексты в ТОП10 и выделить наиболее часто встречающиеся слова. Важное примечание: для анализа следует брать сниппеты некоммерческих сайтов, если продвигаемый сайт является коммерческим, и наоборот (рис. 7).

5. Генератор семантического ядра SeoPult
По сути этот инструмент агрегирует все перечисленные выше способы и исключает рутину. Указав основной запрос в ячейке и нажав кнопку «Семантика», вы за секунды получите список из нескольких десятков LSI-фраз (рис. 8). В их числе будут и синонимы, и расширяющие тематику слова. Фразы можно разбить на составляющие и брать для текста однословные запросы во избежание повторов ключа. Подборщик доступен в модуле контекстной рекламы на шаге 2, блок «Ручной подбор слов».

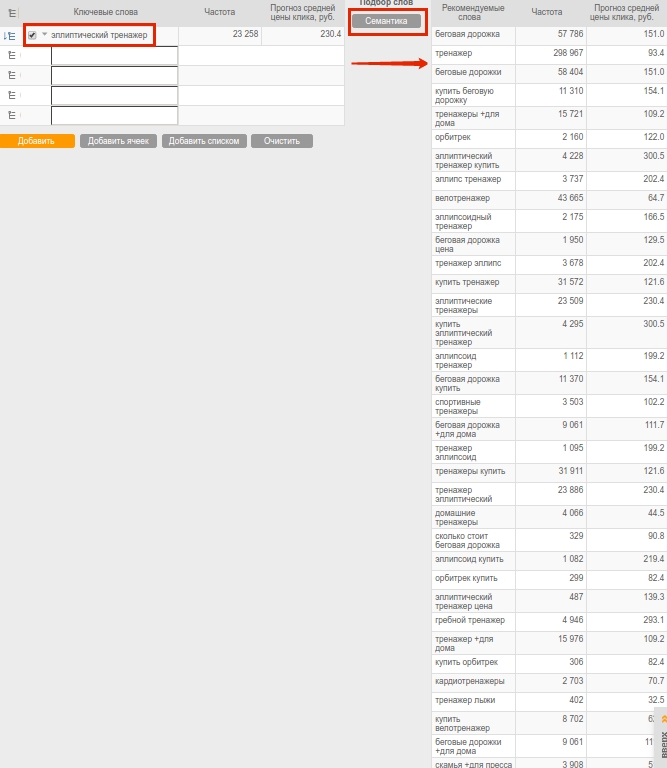
В результате проведенной работы вы соберете довольно широкое LSI-ядро, однако далеко не все слова будут необходимы для конкретного текста. Нужно исходить из задачи и оставлять только те запросы, которые удовлетворят требованиям. Например, описание для раздела каталога магазина и информационная статья о выборе тренажера будут иметь разное назначение и отличный набор фраз.
Найденные LSI-запросы можно использовать не только для написания новых текстов, но и коррекции существующих. После очередного текстового апдейта поисковых машин вполне вероятно, что обновленный контент появится в выдаче по дополненным ключам.
Применяй с умом
Написание текстов на основе LSI-фраз — метод рабочий, но тем не менее не решающий проблему качества контента. Можно собрать богатую семантику для насыщенной и полезной статьи, но применить ее так, что текст невозможно будет читать.
Пример на рисунке ниже является тому подтверждением.


Важно осмысленно подходить к тому, что вы пишите — не нужно превращать текст в бессвязный набор предложений.
Необходимо:
- выделить наиболее релевантные ключи для конкретного материала,
- уместно вписать их в контекст,
- грамотно структурировать информацию,
- использовать приемы визуализации (заголовки, списки, абзацы, графику и проч.),
- изложить материал простым и доступным аудитории языком с соблюдением правил русского языка.
Помните, что ключи можно использовать не только в теле текста, но также в заголовке (Title) и описании страницы (Description), заголовках H1 и подзаголовках.
Только при комплексной оптимизации и регулярном создание новых страниц сайта с тематическим контентом можно рассчитывать на внимание читателей и расположение поисковых машин. В реализации этой задачи вам помогут профессиональные копирайтеры и редакторы.
© Николай Коноплянников, руководитель SeoPult.TV автоматизированной рекламной системы SeoPult