Содержание
Зачем нужна кластеризация
Начнем с определения. Кластеризация — это смысловая группировка ключевых фраз. Внутри каждой группы должны оказаться фразы с одним интентом (потребностью пользователя), но разными по лингвистической конструкции. Например: [мобильный телефон], [сотовый телефон], [смартфон]. Для кластеризации перечень групп не задается, а определяется в процессе работы алгоритма.
Кластеризация нужна при работе с большими семантическими ядрами, чтобы понять, какие запросы можно продвигать на одной странице и какие понадобятся написать статьи для раскрытия тематики сайта.
Есть фанаты, которые группируют слова вручную в Экселе или Кейколлекторе. Да, это больше похоже на кропотливый титанический труд длинною в несколько месяцев — можете попробовать. Но, чтобы правильно распределить ключи, нужно очень хорошо разбираться в теме. Ошибка может обойтись весьма недешево. Именно кластеризация помогает автоматически определить какие ключи будут дополнять друг друга и привлекать поисковый трафик. Если у вас большое семантическое ядро, то вручную проверять каждый запрос, как вы понимаете, не представляется возможным.
Но на этом список плюсов не заканчивается. Еще кластеризация помогает:
- сэкономить массу времени;
- не допустить некоторых ошибок при распределении ключевых слов по группам;
- использовать максимально полный диапазон семантики и тем самым получать максимально возможный трафик;
- избегать смыслового дублирования и как следствие — каннибализации ключевых слов. Каннибализация ключевых возникает когда создано несколько страниц контента под одни и те же ключевые слова;
- оптимально расходовать бюджет на контент, выписывая статьи только для эффективных групп.
Недостатки существующих сервисов
Зачем было создавать еще один инструмент, если на рынке представлено множество сервисов?
Проблема большинства инструментов кластеризации в том, что они формируют группы на основе одной самой частотной фразы.
То есть она является стержнем на который нанизываются другие похожие фразы.
Это плохо тем, что:
- В одну группу попадают фразы, которые не имеют семантической связи между собой.
- Остается много незадействованых кластеров, которые могли бы быть объединены в более крупный.
- Для каждой фразы должна быть снята точная частотность. Это требует дополнительных финансовых затрат на аренду прокси, оплаты за распознавание каптчи и постоянного контроля, чтобы какой-то прокси не отвалился и частотности были собраны корректно.
Основные фишки кластеризатора Serpstat
Serpstat решает эти проблемы через реализацию иерархической кластеризации, при которой близкие по смыслу кластеры, объединяются в суперкластер.
- Serpstat собирает группы не отталкиваясь от самых высокочастотных фраз.
- Анализируются все фразы в целом, которые пересекаются в выдаче.
- Фразы компонуются иерархически. Наименьшие группы собираются в кластер, кластеры группируются в суперкластеры, а суперкластеры объединяются в группы еще более высокого уровня — протокластеры. Это очень круто, потому что если останутся какие-то висячие фразы, вам будет проще их вручную раскидать по имеющимся группам.
- Serpstat проверяет силу связи между всеми фразами, в соответствии с заданными вами настройками.
Как избавиться от рутины
Сгруппируйте ваши фразы по смыслу автоматически. Теперь Serpstat за вас сгруппирует тысячи слов, а результаты разбивки всегда можно отредактировать и экспортировать. Начните работу с создания списка ключевых запросов.
От вас не требуется ни дополнительный сбор частотности, ни какая-либо предварительная подготовка данных — вы просто загружаете список фраз, выбираете регион и способ кластеризации.
Фантастика? Попробуйте сами!
Сколько это стоит
Стоимость использования «Кластеризации» включена в стоимость вашего тарифа.

- В плане А нет возможности кластеризовать фразы.
- План B включает 4000 ключевиков на кластеризацию.
- План С — 12 000 фраз.
- План D — 25 000 фраз.
Внимание! Пока инструмент находится в режиме Beta, стоит ограничение — в одном проекте нельзя группировать более 2 тыс. фраз.
Зерегистрируйтесь в и оплатите тариф Plan B или выше.
Вам будет доступно для кластеризации и проведения текстовой аналитики 4000 ключевых фраз на период действия тарифного плана. Текстовая аналитика будет доступна после проведения кластеризации ключевых фраз.
В бесплатном тарифе и Плане А вместо кнопки «Открыть» будет написано «Свяжитесь с нами».
Как пользоваться модулем «Кластеризация»
Перейдите в раздел «Инструменты».
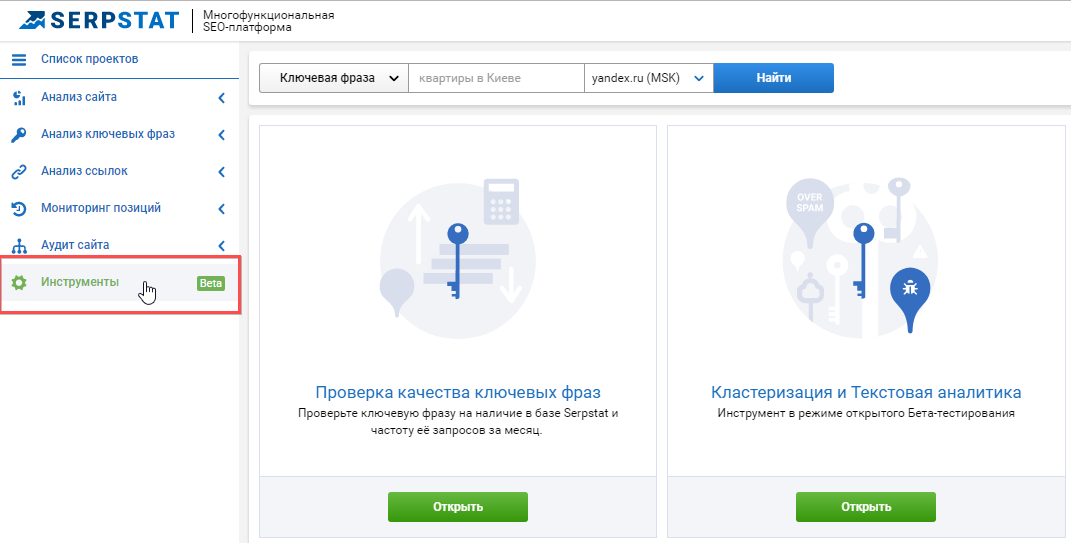
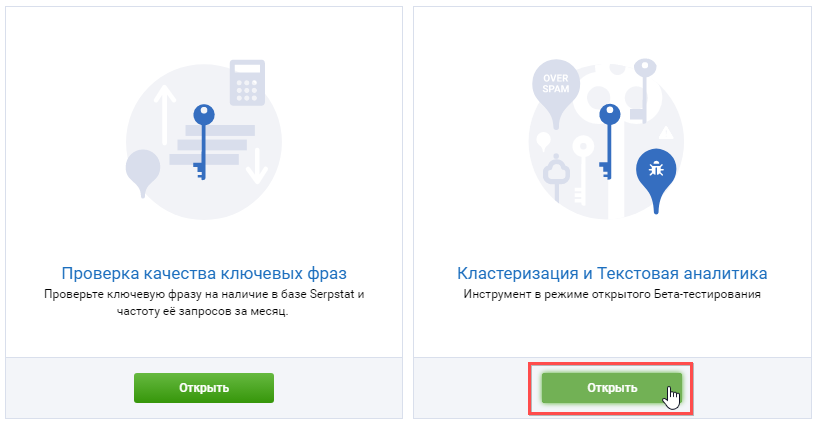
В блоке «Кластеризация и Текстовая аналитика» нажмите на кнопку «Открыть».
Нажмите на кнопку «Создать проект».
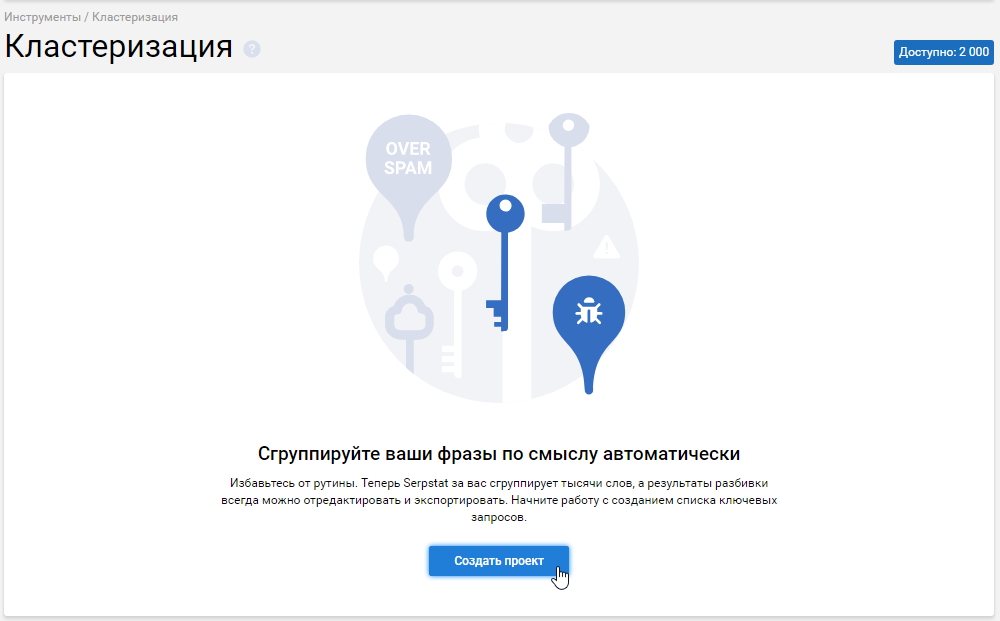
Задайте имя вашему проекту.
Домен указывать не обязательно. Но если есть указать, то это позволит вам автоматически прикрепить страницы вашего домена к группам.
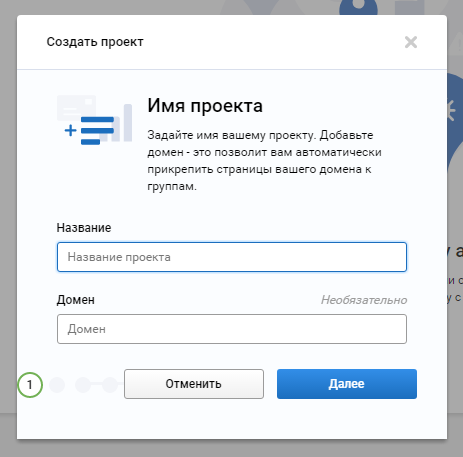
«Кластеризация» находится в режиме открытого бета-тестирования, поэтому для группировки пока можно загрузить не более 2000 фраз.
Вы можете добавить ключевые фразы вручную или импортировать их из файла.
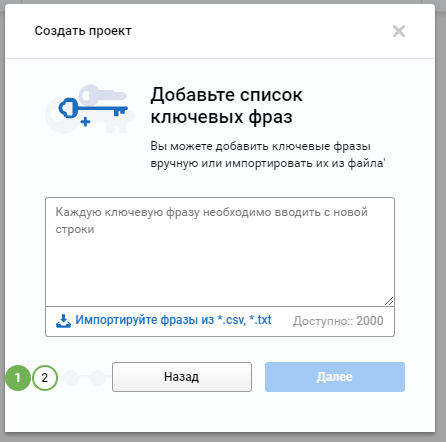
Если все сделано правильно (импортируемый файл соответствует допустимому формату, количество фраз не выходит за тестовый диапазон), то кнопочка «Далее» будет доступна.
Выберите поисковую систему и регион, в котором сайт будет продвигаться. Чтобы не перелопачивать весь список доступных городов, начните набирать его название. Так вы быстрее найдете нужный.
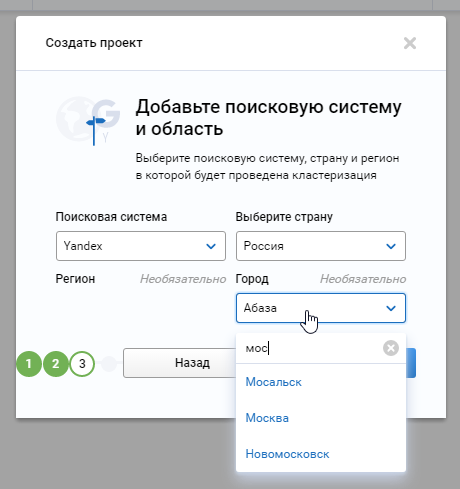
На данном шаге все выбрано, жмем кнопку «Далее».
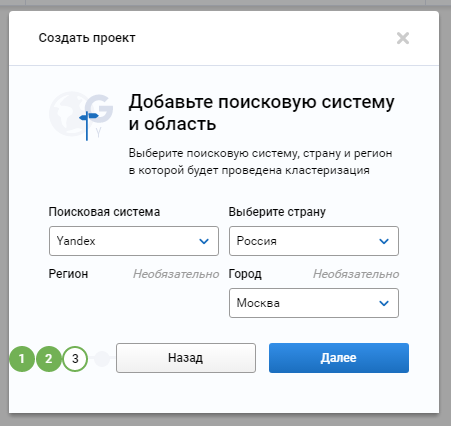
Устанавливаем силу связи и тип кластеризации. Выберите режим в котором будет проходить процесс кластеризации.
| Тип связи | Режим объединения |
| Weak — слабая связь между фразами. | Soft — запросы объединяются в группу, если есть общий набор URL хотя бы для одной пары. |
| Strong — сильная связь между фразами. | Hard — запросы объединяются в группу, только если есть общий для всех набор URL. |
Для информационных сайтов лучше подходит пара Weak+Soft. Для коммерческих — Strong+Hard.
Выставили? Жмем на кнопку «Готово»!
Ахтунг! Как вы думаете, что должно появится на последнем шаге, после того как вы нажали на кнопку «Готово»? Наверное окно с сообщением о том, что проект успешно создан и процесс кластеризации начался и результаты станут доступны через некоторое время, о чем вы будете уведомлены по почте? Да, так и должно быть. Но, пока это не так (видимо это первый глюк на стадии бэта-тестирования). Возникает ощущение аварийного завершения работы и опасения, что настройки проекта не сохранились.
Не спешите переживать! На самом деле проект уже в работе. Чтобы увидеть его в списке, просто обновите страницу.
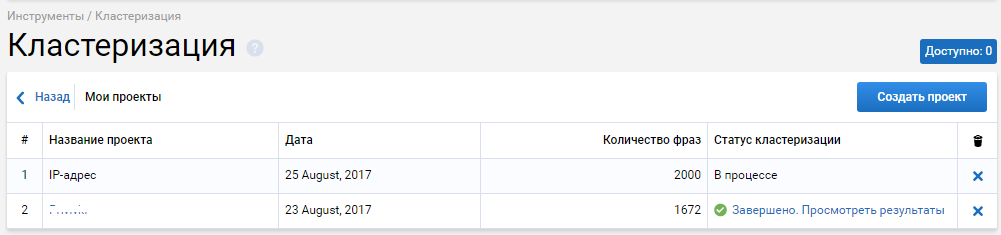
В первом проекте отображался зелененький прогресс-бар, который отображал ход процесса, который длился 16 минут. А в этот раз уже в течение 30 минут указан просто статус «В процессе». Саппорт говорит, что для 2 000 фраз это допустимое время. Проект в очереди. Сама кластеризация выполняется быстро, но пробивка топов занимает определенное время.
В общем проект кластеризовался.
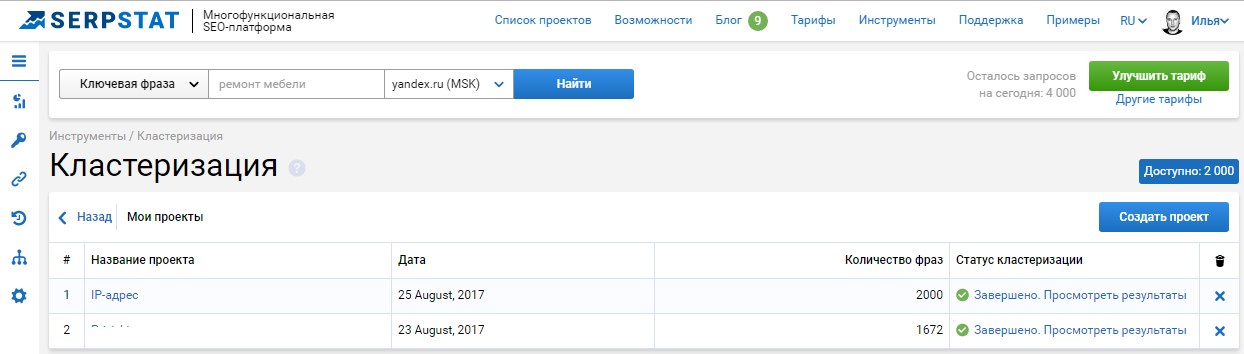
Кликаем по ссылке «Завершено. Просмотреть результаты».

Сгруппированные данные будут представлены в таком виде: слева кластеры, суперкластеры и протокласетры, а справа — содержимое каждого кластера. Можно изменять название кластеров, создавать новые, открыть к просмотру все кластеры и скрыть некоторые.
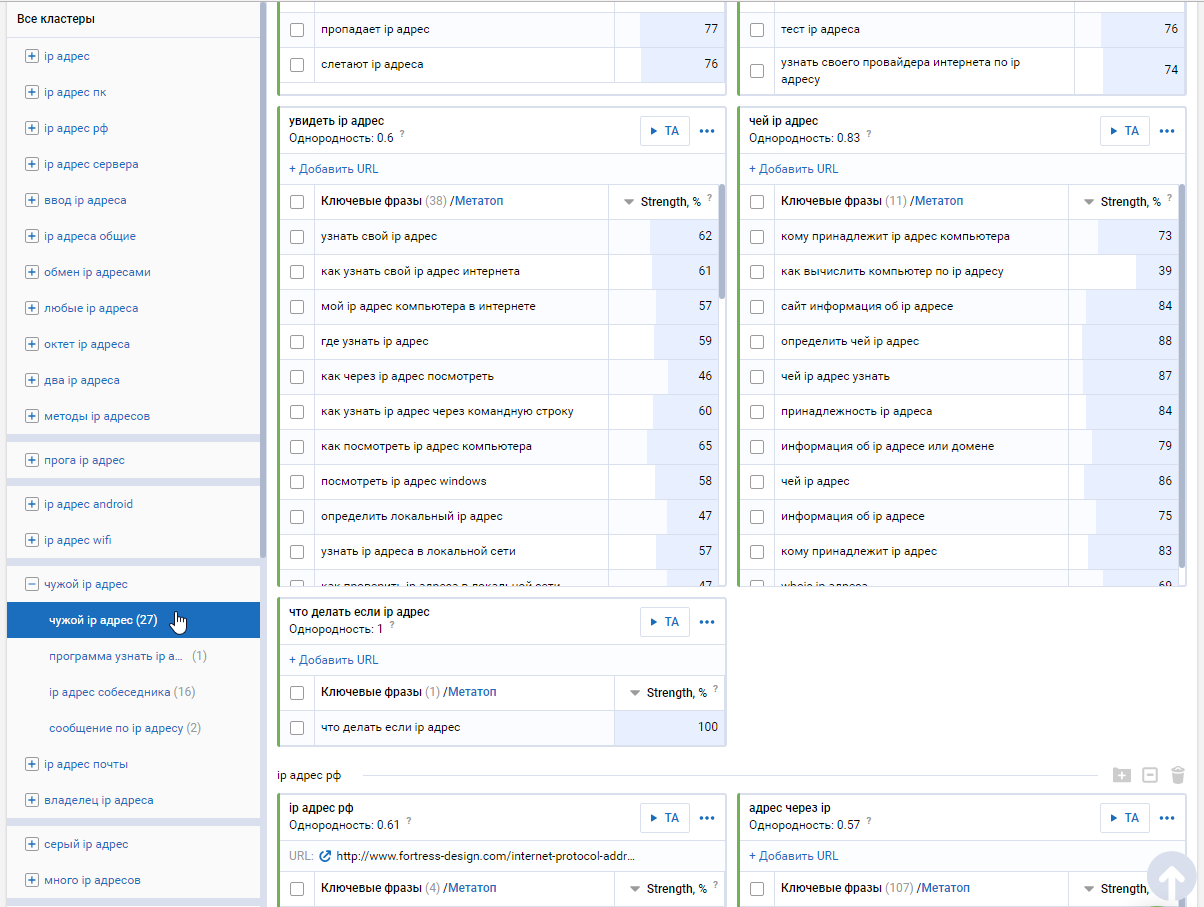
В столбце «Все кластеры» группы имеет такую иерархию.
- Кластер.
- Суперкластер — набор кластеров. Суперкластер объединяет близкие по смыслу фразы, но немного менее синонимичные, чем непосредственно фразы из кластера.
- Протокластер — набор суперкластеров. Как правило, в протокластер объединяются суперкластера, представляющие определенную категорию объектов.
Содержимое каждого кластера содержит сводную информацию по кластеризации:
- Однородность — на сколько связаны по тематике ключевые фразы
- Сила связи — насколько каждая ключевая фраза близка к тематике кластера
- Количество ключевых фраз в кластере
- Метатоп — список ТОП сайтов, по которым формировались группы. Чем выше страница находится в метатопе, тем более релевантна она тематике данного кластера фраз.
Дополнительно есть возможность добавить УРЛ страницы, на которую нужно посадить эти запросы. Помните, выше, при создании проекта была возможность указать адрес сайта? Вот если это сделать на том этапе, то адрес посадочной страницы был бы подставлен автоматически (это актуально для существующего проекта).
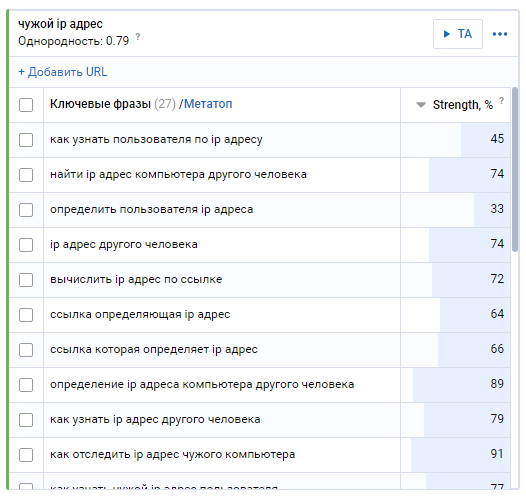
Текстовая аналитика
Кроме этого каждый для каждого кластера можно провести текстовую аналитику, нажав на кнопочку → ТА.
Стоимость данной процедуры рассчитывается в соотношении 1 запрос = 1 лими
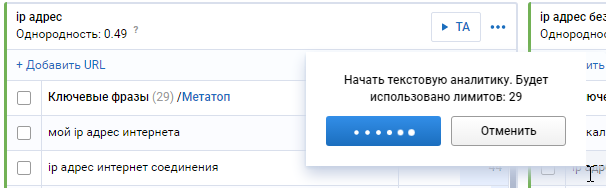
Через некоторое время будут доступны результаты.


Кроме анализа ключевых фраз отдельно даются рекомендации со списком слов для использования в тайтле, h1 и теле статьи. Для существующего проекта можно сделать анализ текста на конкретной целевой странице. Вам остается добавить ссылку и запустить анализ.
Таким образом с помощью Serpstat без дополнительных затрат и времени вы в одном сервисе проходите все этапы составления СЯ и адаптации полученных групп под конкретные страницы.
Потестить кластеризацию