Содержание
Группировка однотипного товара
Часто встречаются ситуации, когда магазины продают однотипный товар, отличающийся только модификациями. Например «чехлы для телефонов». У нас есть чехлы для iPhone, LG, Samsung и т. п. При этом каждый бренд разделяется на модели, а модели, порой, дополнительно дробятся на модификации. И не важно, что чехол для Айфона отлично налезает на Samsung. Пользователи ищут чехол именно на свой телефон. И набирают в поиске именно свою марку и модель телефона.
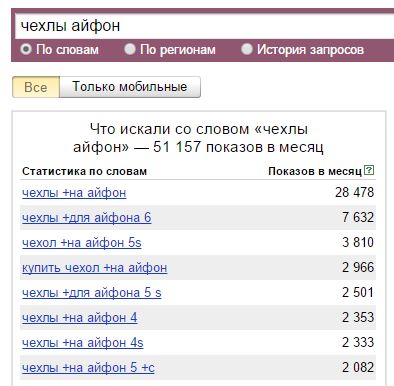
Проектирование структуры сайта
Про пользу точной сегментации аудитории мы сейчас тоже говорить не будем  В итоге мы предварительно можем запланировать вот такую структуру сайта
В итоге мы предварительно можем запланировать вот такую структуру сайта
Теперь нам нужно собрать СЯ. И мы можем пойти разными путями.
Как собрать семантическое ядро
Первый способ
Первое, что приходит в голову, это просто начать собирать ключи для каждой посадочной страницы по отдельности, банально забивая стартовый ключ. Так мы сразу и соберем запросы, и рассортируем на группы по посадочным страницам. Например «чехол для Айфон 5 С». Но посмотрите на скрин:
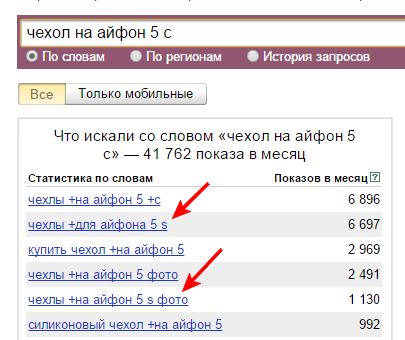
Тут мы видим, что к «5 с» примешались и 5 и нам потом все равно придется чистить эту группу запросов.Кроме того, когда мы начнем собирать запросы для верхних групп, в которых пользователь не указывает модификацию и модель телефона, то рискуем заново собрать все те запросы, которые уже собирали.
Да, в КейКоллекторе есть кнопка «Не добавлять фразу, если она есть в любой другой группе», однако при сборе Кейколлектор все равно будет цеплять эту фразу и сравнивать с теми, что уже есть. Это дополнительные операции и увеличение времени работы программы. Особенно, если у вас не 7 групп, а несколько сотен
Второй способ (и достаточно популярный)
Мы создаем шаблон, куда забиваем возможные слова для сочетания с нашими ключами. Например:
- купить
- купить не дорого
- магазин
- силиконовые
- книжка
- и т. п.
Далее генерируем ключи подставляя указанные выше слова к модификациям телефона. Получаем что-то вроде этого:
«купить чехлы на айфон», «купить недорого чехлы на айфон», «силиконовые чехлы на айфон». Снимаем частотности и вот, вроде, готовое СЯ.
Однако у этого способа недостатков еще больше.
- Во первых несогласованность некоторых слов с ключами. Например «магазин чехлы на айфон». Правильно будет «магазин чехлОВ на айфон».
- А во вторых, работая таким методом мы упускаем огромное количество поисковых запросов, которые набирали пользователи, но о которых мы можем даже не подозревать. Например «чехлы на айфон со стразами». Слово «стразы» не входило в наш список слов, и мы просто упустили этот ключ.
Третий способ
Мы просто собираем все подряд! Для этого нам не нужно придумывать слова для шаблона, мы не будем на данном этапе заморачиваться с группами. Мы соберем все ключи, которые касаются запросов «чехлы айфон». Единственный труд, который мы себе дадим, это при сборе напишем слово «Айфон» два раза — латиницей и кириллицей. Ну и клацнуть по соответствующей кнопке в КК.
И так, КейКоллектор у нас отработал, и мы получили список из запросов при сборе выставлял регион «Москва и область»).
Если сейчас представить, что это все нам предстоит очистить от мусора и раскидать по группам, то сразу хочется удавиться. Однако не спешите сводить счеты с жизнью, или профессией. У нас есть замечательный инструмент!
Мы будем использовать вкладку «Стоп слова» в Кей Коллекторе. Чаще всего эта вкладка используется на этапе сбора ключей и/или последующей фильтрации. Этой стандартной функцией воспользуемся и мы.
Быстро просматриваем список запросов, и вылавливаем слова, которые явно не относятся к продажам нашего товара. Например «фото», или кастомизация чехлов — «с фамилией» и т. п.
Забиваем эти слова в список стоп слов, отмечаем галкой и удаляем лишнее.
С вероятностью 99.9% вы пропустите больше половины возможных стоп слов
Пора выдавать обещанные секреты
Как быстро выбрать стоп слова из списка запросов
Если мы начнем поштучно отбирать стоп слова и удалять фразы, где они присутствуют, то увидим, что более 90% стоп слов встречаются в одном, или двух ключевых запросах. Соответственно нам нужно:
- Взять весь список запросов
- Разобрать его на слова
- Посчитать количество вхождений каждого слова
- С чистой совестью выбрать все слова, которые встречаются один или два раза и забить их в список стоп-слов.
Основная сложность как раз в разбивке текста на слова и подсчет встречаемости.
Я пробовал разные онлайн-сервисы по анализу текста, но ни один из них не счел достаточно удобным. Везде приходилось так или иначе что-то допиливать в этом списке стоп слов.
Например широко известный сервис Адвего даст нам вот такой список слов:
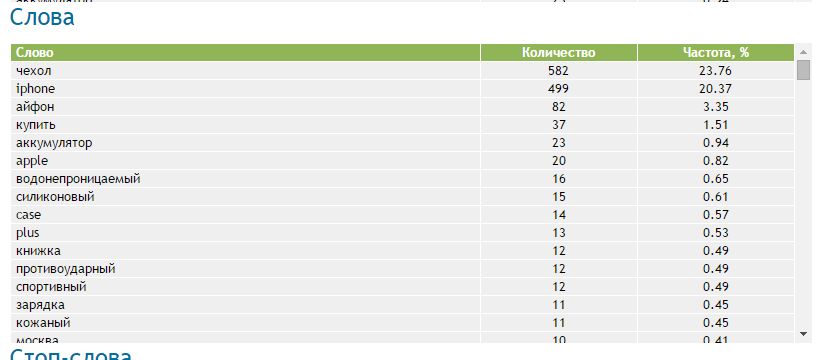
Этот список можно скопипастить в Эксель, убрать цифры и дальше воткнуть во свкладку «Стоп слова». Но обратите внимание, что слова здесь приведены к исходной словоформе. И при фильтрации КК часть слов просто не зацепит. Нам нужны слова именно в том виде, в каком они встречаются в самих запросах.
Как уже сказал, ни он-лайн сервисов, ни программ я не нашел, которые бы решали эту задачу (может плохо искал, или банально не в курсе возможностей какого либо софта). Поэтому идем малость через Ж
Есть замечательная программа ТекстусПРО www.blog-kaplunoff.ru/programmy-dlya-kopirajterov.html. Программа бесплатная, смело качайте и ставьте.
Открываем программу и в окно для вставки текста вставляем наш список запросов.
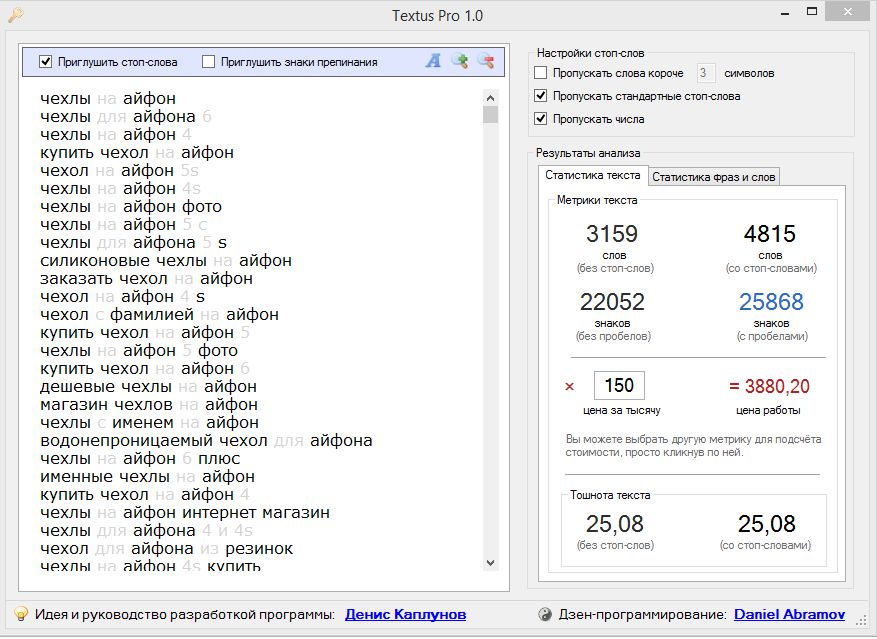
- Во первых, программа сама пропускает все стандартные стоп-слова (в данном случае стоп-слова, это «в, на, для, 4,5 и т.д.»).
- Во вторых она разобрала наш текст на слова и посчитала количество вхождений каждого из них. Переключаемся на вкладку «Статистика фраз и слов»
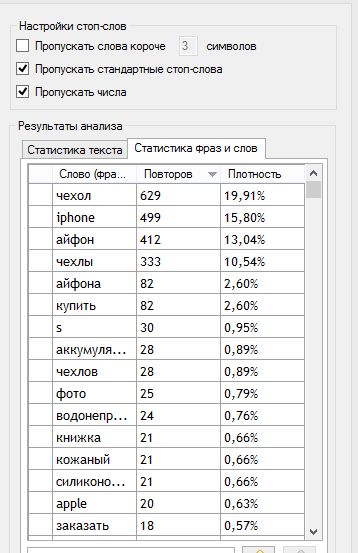
Это как раз то, что нам нужно. Самый большой минус этой программы в том, что тут нет экспорта. Поэтому продолжаем делать через Ж
Используя Shift выделяем все слова. Далее жмем ctrl+C. Все слова у нас скопировались в буфер обмена.
Открываем Эксель (или как у меня ОпенОфис) и жмем ctrl+V
Получаем:
Упс! Не воспринимается кодировка. Поэтому продолжаем углубляться в Ж
Открываем блокнот и вставляем туда все, что скопировали:
В блокноте у нас все чисто и красиво. И вот теперь уже в блокноте копируем весь наш список (жмем ctrl+A, ctrl+C) и вставляем в электронную таблицу:
И так, мы получили рабочий файл. И смею уверять, что делать вы его будете быстрее, чем сечас читали
Теперь мы удаляем те слова, которые нам нужны в нашем семантическом ядре. Не перепутайте! Удаляем то, что нам нужно!
Получается примерно так:
Самые важные и нужные слова будут вверху списка. Поэтому как доберетесь до встречаемость в 1 или 2 вхождения, то можно дальше не смотреть.
На эту операцию уходит пять минут (и то, если перепроверить раза три)
Все. Наш список стоп-слов готов. Копируем его из таблицы и вставляем в список в соответствующей вкладке КК
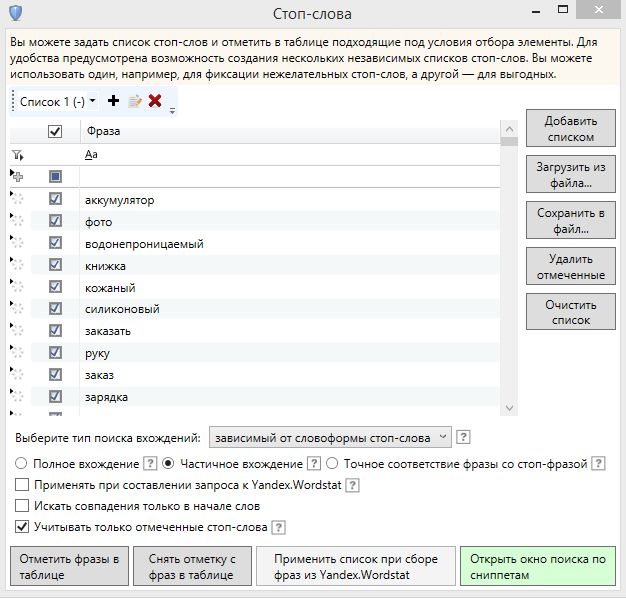
Кликаем по кнопке «Отметить в таблице» и все фразы, содержащие стоп-слова у нас будут отмечены. Теперь их можно удалить. Но я бы этого не рекомендовал. Во первых не исключена ошибка и мы могли что-то пропустить. Во вторых, сайт может развиваться и впоследствии добавятся еще и виды чехлов — силиконовые, кожаные, деревянные и т. п. (на данном этапе это все попало в стоп слова). Ну и в третих, все эти ключевые фразы можно потом использовать для разбавки анкоров покупных ссылок.
Поэтому кликаем по кнопке «Перенос фраз в другую группу». Там кликаем «Создать группу», пишем название и переносим
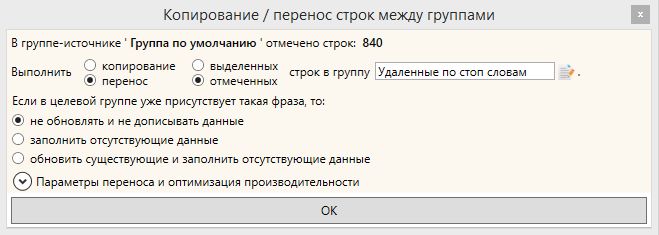
Итак, буквально за 10 минут и несколько кликов мы очистили список состоящий из 999 запросов от всякого мусора и получили вполне рабочий список из 159 запросов
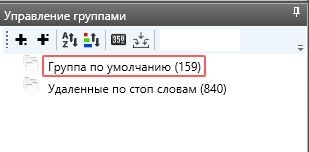
При беглом просмотре рабочего списка ключей видим, что туда затесались айфоны 2 и 3. Они нам не нужны. Опять открываем вкладку «Стоп слова», создаем второй список и просто прописываем цифры 2 и 3
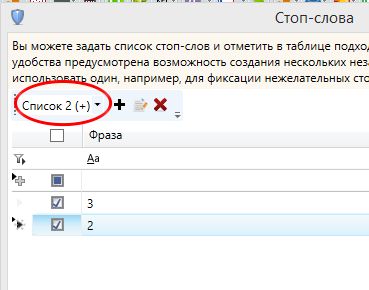
И точно так же фильтруем и переносим в группу «Удаленные». Итого у нас осталось 147 ключей, которые теперь нужно раскидать по группам.
Группировка поисковых запросов
Начинаем группировать наши ключи. И тут мы опять используем кнопку «Стоп слова». По сути «Стоп слова» это самый обыкновенный фильтр, но очень удобный в работе.
Открываем вкладку и создаем еще один список, куда заносим модели и модификации
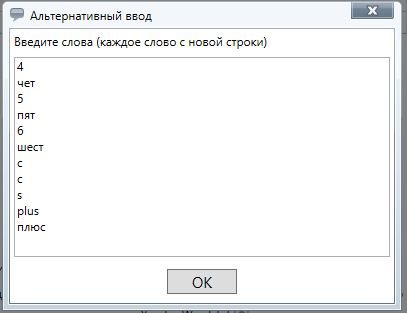
Букву С я вбил два раза — один вариант кириллицей, другой латиницей.
Теперь выбираем модель — 4 айфоны. Отмечаем галкой 4 и слово «чет» и кликаем «Отметить в таблице».
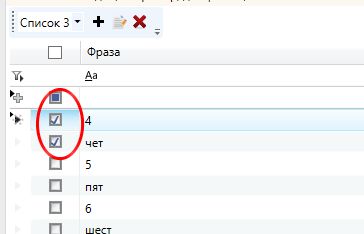
И у нас все запросы, где присутствует цифра 4, или прописью фигурирует «четыре, четвертый» будут отмечены в таблице.
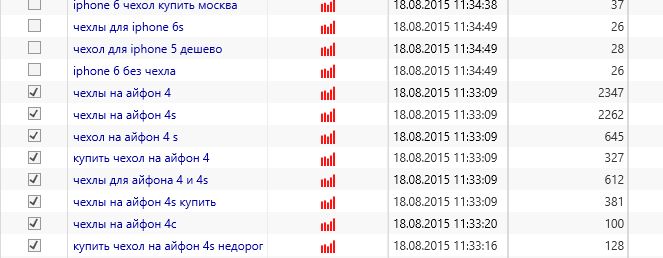
Далее кликаем «Перенос фраз в другую группу», «Создать новую группу». Пишем назвние группы — 4 айфон и переносим туда все отмеченные запросы.
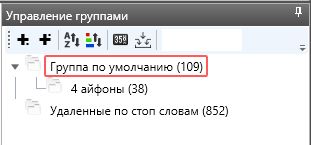
Аналогично поступаем с 5 и 6 айфоном.
И так, у нас получилась верхняя общая группа, где есть ключи «чехлы для айфон» без указания конкретных моделей. И три группы по моделям.
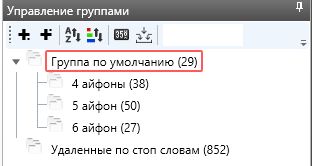
Группы стали меньше и работать с ними стало проще. Сразу видны другие стоп-слова, которые мы все таки пропустили Например «чехол для iphone 7». Тут уже можно руками отметить и удалить лишнее.
Теперь нам нужно рассортировать модели по модификациям. Делаем все тоже самое.
Заходим в группу с 5 айфоном, открываем стоп-слова, выбираем S и С (латиница и кириллица), отмечаем и переносим в новую группу, которую создаем внутри группы «5 айфоны». Аналогично поступаем c другими группами.
В результате опять получаем верхнюю группу, где пользователи указали модель айфона, но не указали модификацию. И две группы с модификацией.
Проделываем все тоже самое для остальных подкатегорий.
В результате, буквально за несколько кликов, мы получили обширное и разгруппированное СЯ.
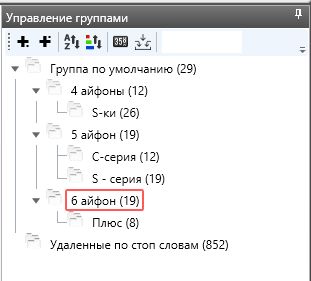
При этом большую часть времени занимает непосредственно сбор ключей КейКоллектором. Однако, если у вас настроены прокси и работа идет в несколько потоков, то и сам сбор займет не так много времени.
Автор:
Комментарии
- разбить на структуру сайта
- делать серч по общим ключам
- собирать статистику
- фильтровать по общим ключам => вытаскивать нужное в отдельную общую папку
- фильтровать по запросам => вытаскивать нужное в отдельную общую папку
Единственный минус такого подхода, при большом количестве кейвордов статистика будет собираться долго. Не усложняет ли процесс эти стоп слова?
Тут как раз особенность в том, что не все стоп слова мы выкидываем. Что-то оставляем. Кроме того, чисто по практике, стоп-слова, которые нам не нужны, как правило повторяются и для других категорий товаров. Например «водонепроницаемый» будет актуально для всех марок телефонов. И этот стоп-лист мы в дальнейшем уже можем использовать при сборе запросов для других брендов телефонов.
Я обычно после КК в экселе просто раскидываю на группы…
Сергей Анисимов
Ну у Вас же на скрине образовались группы «на» и «для». Вас такой результат устраивает?
Андрей Тарасов
почистите их, изначально и выделите только те группы для которых нужно создать подгруппы, все сочетания «на» «в» перенесутся с корневыми группами, хлам на удаление.
Ну а зачем еще какие то телодвижения? Мы сформировали структуру сайта, мы сделали два списка стоп-слов, и за 10 минут получили готовый результат.
Повторюсь: мне не нравится, как КК разбирает запросы на группы. И не стоит меня упрекать в том, что я не читал мануал. Читал.
И не писал бы статью, если бы мог получить нужный мне результат с помощью данной функции программы.
Андрей Тарасов
Сергей, а зачем телодвижения с импортом, экспортом в разные программы и разбором кодировок?
А функцией «Анализ групп» воспользоваться религия не позволяет? Или группой распределения запросов по группам?Кстати, от туда же можно добавить и в стоп-лист, и распределить по группам
Андрей Тарасов
Сергей, объединять группы тоже можно с помощью kk и еще, можно в вордстат посылать такие запросы Кондиционер (авто | машина)
А то стыдно за page-weight
Сергей Анисимов
Андрей, я Вам выше в комментах ответил.


