
Содержание
Как Ашманов и партнеры анализируют данные
В «Лаборатории поисковой аналитики» постоянно проводятся исследования результатов поисковой выдачи в Яндексе, Google, Mail.ru по коммерческим запросам. Выдачу можно сравнивать по разным параметрам; сейчас их количество перевалило за 600. Анализируем всё: коммерческие параметры, ссылочные, текстовые, трафиковые, поведенческие, технические.
Для каждого из трех поисковиков (Яндекс, Google, Mail.ru) проверяем:
- есть ли статистически значимая связь между значением параметра и попаданием в топ-30;
- есть ли корреляция с позицией внутри топ-30.
В 2017 и 2018 году выходили подробные аналитические отчеты, которые выложены на наш сайт.
В этом докладе остановимся на текстовых параметрах.
Типичный текстовый параметр

Посмотрим на примере конкретного параметра — количество вхождений слов запроса и их синонимов в текст найденной страницы.

Влияние этого параметра очень высоко. На верхней диаграмме указаны значения слева для Google, справа для Яндекса. Верхняя линейка — топ-3, дальше топ-30, самая нижняя — «фон» (то, что попало в топ в других поисковиках, а в этом нет).
Видно, что из слов запроса и синонимов в сумме набирается где-то 30-40 запросов. Считается это так. Если запрос из трех слов, то, в зависимости от частотности этих слов, кому-то из них дается вес, например, 0,4, кому-то — 0,2. Дальше каждое вхождение слова или его синонима мы засчитываем за тот вес, который ему приписан. В сумме набирается на 30-40 запросов. Это на самом деле очень много. И если мы возьмем другие параметры, то тоже цифры окажутся большими.
На оранжевых диаграммах внизу — средние значения по позициям на нашей стандартной выборке, которая ничем особо не хороша, кроме того, что мы за ней наблюдаем уже почти четыре года.
Слева Google. Видно, какая сильная корреляция с позицией. Значение корреляции (это ранговый критерий Спирмена) выписано у треугольничка на верхней диаграмме — в данном случае это значение 0,22 (и это очень много). Но при этом в Google средние значения меньше, чем в Яндексе, у которого есть статически значимая связь с попаданием в топ-30 и есть небольшая корреляция с позицией, гораздо более слабая. И мы считаем, что в данном случае вероятное влияние на попадание в топ в Яндексе важнее, чем влияние на позицию в Google.

Как ранжируется по разным параметрам и по разным зонам страницы? Главная вещь, которую про это можно сказать, можно назвать принципом антибуквализма.
Прошли те времена, когда нужно было, чтобы ключевик в точной форме определенное количество раз встретился в тексте. На самом деле, он все равно встречается довольно часто — у нас получается где-то 3-4 раза на страницу. Но при этом корреляции слабые. Два перечеркнутых треугольника — это отсутствие корреляции.
Видно, что в Яндексе корреляции начинают возникать при подъеме по этому треугольнику, а внизу их просто нет. В Google они усиливаются. И точно также в какой-то момент в Яндексе начинает возникать связь с попаданием в топ-30, а для нижних параметров ее нет.
Кроме того, важны не только и часто не столько слова запроса, но и другие слова, которых в запросе нет. Мы смотрим на две группы слов — это синонимы слов запроса и слова, которые выделяют в сниппетах Яндекс и Google. И часто оказывается, что попадание этих слов, которых в запросе нет, важнее, чем попадание самих слов запроса.
Можно предположить, что, кроме этого, важны еще какие-то другие слова, но на это нет параметров.
Посмотрим, что получилось в Google:

Буквами «Т» обозначена связь с попаданием в топ, буквами «П» — корреляция с позицией. Есть четыре градации для каждого случая. Две буквы — сильная, одна большая буква — средняя, одна маленькая буква — слабая, и бледная маленькая — на нашей выборке корреляции не видно, но она видна на больших выборках. Параметр, который мы смотрели, выделен полужирным — текст страницы.
Сводная таблица Яндекса:

Что здесь важно? На Google в основном буквы «П», на Яндексе — «Т». Грубо говоря, в Яндексе это смотрится в основном при предварительном отборе, когда мы, например, выбираем 1000 страниц для дальнейшего подробного ранжирования. И гораздо меньше влияет на позицию при выборе, кого показать выше, кого ниже. А в Google какие-то текстовые факторы в полный рост влияют на окончательное ранжирование. И меньше влияют на предварительном этапе, если влияют. И на той, и на другой картинке принцип антибуквализма очень хорошо виден — справа налево усиливается густота букв.
Есть одно важное исключение из этого принципа. В Google точный запрос без форм, прямо как встретилось, оказывается очень важным (потому что буква «Т» вообще важнее, чем буква «П») в title. И немного в H1 и в description в меньшей степени. Это надо учитывать.
Оказывается довольно мало важен в Яндексе H1, как и H2-H4. И title тоже неубедительный. Про keywords видно, что они, скорее всего, просто не работают.
Еще бывают попадания слов запроса в доме и в URL.
Домен и URL

Домен важен и там, и там. URL не виден в Google, но это может быть из-за того, что Яндексе он важнее. То есть, может быть, он влияет на попадание в топ как-то, но в Яндексе чпу-URL крайне важны. И там в основном буквы «Т». То есть, они важны на предварительном отборе. И обратите внимание на высокие цифры. В части адреса после домена в среднем набирается на треть запроса слов. На самом деле, этого очень много.
Вторая вещь, которую обязательно надо учитывать — важна не только страница, на которую мы смотрим, но и весь сайт.
Подсайт и сайт

Очень важный параметр и с очень большими значениями — верхняя строчка — это сколько страниц найдено с сайта релевантных запросу. Важно, сколько внутренних ссылок на сайте — без привязки к текстам. Выигрывают те страницы, на которых их много. И слов запроса во внутренних ссылках тоже очень много. И то, что высокая значимость элементов списка, это тоже, скорее всего, про это.
SEO-тексты
Приведем пример типичного seo-текста в интернет-магазине.

Что об этом можно сказать? Когда мы делали сервис «Тургенев» для проверки текста на риск «Баден-Бадена», мы продумали много разных параметров о текстовой спамности и качестве текста. Мы их делали для себя, чтобы научиться оценивать качество текстов.
Выяснилось, что они неплохо цепляют какие-то тонкие струны души поисковиков.

По многим из них оказываются или корреляции с позицией, или связь с попаданием в топ. Особенно порадовала выделенная жирным в четвертой строчке снизу очень сильная связь с параметром плотности стилистических проблем в тексте.
Как это делалось? Брали большой словарь разных стилистических ошибок, и смотрели, какое количество текста ими покрыто. Выяснилось, что Яндекс к этому неравнодушен (что очень приятно). Вторая вещь, которая очень порадовала — цифра 7,91 в верхней строке. Мы прикинули, когда начинаются совсем плохие тексты после того, как мы им поставили баллы. Поставили порог сильного риска «Баден-Бадена» — 8. В среднем в Яндексе сейчас получается 7,91.
Теперь та же таблица, в которой появились две лишних строчки. Одна — seo-текст, другая — текст за вычетом seo-текста.
В Google: сильнее текст
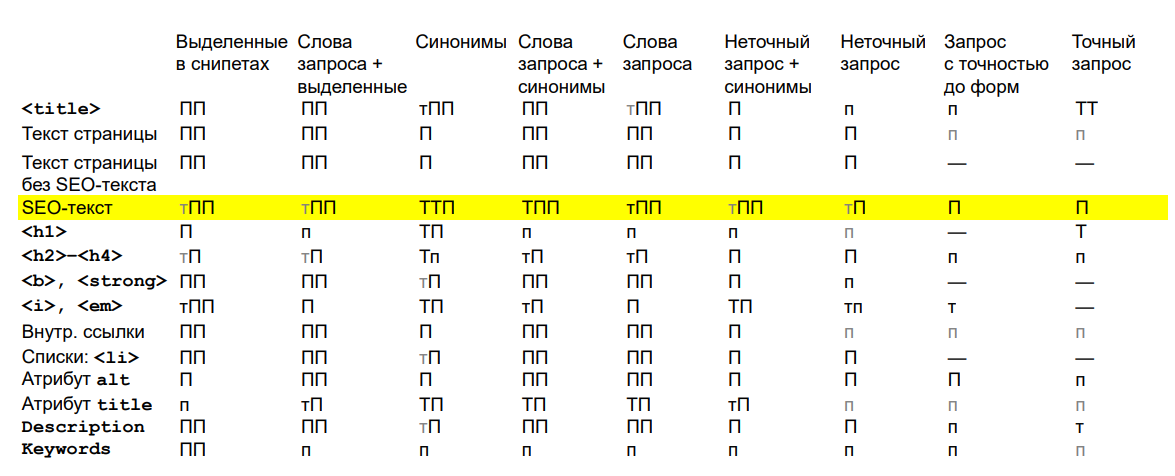
Что мы видим? В Google основной блок с seo-текстом ранжируется сильнее, чем собственно текст. Количество букв «П» гуще, где-то буквы «Т» появляются. А если его вычесть, получается немного пожиже, хотя не сильно.
В Яндексе иначе: полный игнор!

В Яндексе — прочерки. Ни корреляции с позицией, ни связи с попаданием в топ не видно. А вот если вычесть блок seo-текста, то получается лучше, чем просто текст.
Похоже, что действительно, прежде чем запускать «Баден-Баден», Яндекс научился выделять текстовый блок и игнорировать его.
Похоже, что, когда вы заказываете копирайтеру seo-текст, он на позиции в Google влияет, а на попадание в топ Яндекса — практически нет.
Немного про Тургенева
Это наш сервис, который оценивает риск «Баден-Бадена». Рассмотрим в нем текст про кофе.

В этом тексте риск 19 баллов, это очень много. Проблемы с повторами, стилистикой и запросами.
Начнем с повторов.

В тексте нет сверхчастых слов, но очень много повторов, таких, которые влияют на метрику «академическая тошнота». Это плохо.
Есть большие проблемы со стилистикой.

Много слов и выражений, которые либо непосредственно плохи (например, «вкусовые качества», «вы можете быть уверены, что приобретаете») или просто часто встречаются в не очень хороших текстах.
Есть проблемы с запросами.

В «Тургеневе» эта вкладка умеет конструировать и длинные запросы из ядер и модификаторов, подключая частые словосочетания из текста. Здесь текст оказался покрыт длинными запросами, за что и получил баллы. Все эти ошибки нужно исправлять.
О seo-текстах рассказал Михаил Волович, руководитель «Лаборатории поисковой аналитики» на конференции Optimization в своем докладе «SEO-тексты глазами Яндекса, Google и «Тургенева». Презентация доклада на сайте конференции.



Это же основа основ))
Не факт. Особенно в некоторых тематиках. Сливинский на презентации приводил примеры агрегаторов контента, где практически не было текстов, но было много графиков. аналитики и прочего. Пользователь получал максимально полную информацию, поэтому такие страницы высоко ранжировались в Яндексе.